- Published on
Unlocking the Secrets of Machine Learning: Techniques for Interpreting Complex Models
- Authors
- Name
- Parth Maniar
- @theteacoder


Introduction
Model interpretability is an increasingly important topic in the field of machine learning. As models become more complex, it can be difficult to understand how they are making predictions, and what factors are driving those predictions. This can be a problem when trying to use machine learning models in real-world applications, such as healthcare or finance. In this blog post, we will discuss some techniques for making machine learning models more interpretable, and we will provide code snippets to demonstrate how to use these techniques.
Techniques for making models more interpretable
LIME (Local Interpretable Model-Agnostic Explanations)
One of the most popular techniques for making machine learning models more interpretable is LIME (Local Interpretable Model-Agnostic Explanations). LIME is a method for explaining the predictions of any machine learning classifier, and it works by approximating the model locally around the point of interest (i.e. the instance for which we want to explain the prediction). The basic idea is to train an interpretable model on a small neighborhood of the instance of interest, and then use this interpretable model to explain the prediction of the original model.
Here is a code snippet that demonstrates how to use LIME to explain the predictions of a machine learning model in Python:
from lime.lime_tabular import LimeTabularExplainer
explainer = LimeTabularExplainer(X_train,
feature_names=boston.feature_names,
class_names=['price'],
categorical_features=categorical_features,
mode='regression')
# Now explain a prediction
exp = explainer.explain_instance(X_test[25], regressor.predict,
num_features=10)
exp.as_pyplot_figure()
from matplotlib import pyplot as plt
plt.tight_layout()
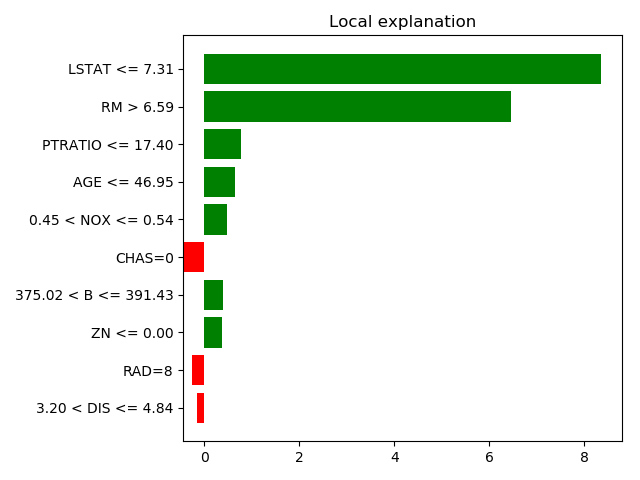
In the above code snippet, we are using the LIME (Local Interpretable Model-Agnostic Explanations) library to explain the predictions of a machine learning model for tabular data and regression problem. It creates an instance of the LimeTabularExplainer class and passing in the training data, feature names, class names and categorical features. It then uses the explain_instance method to explain the prediction of a specific data point, passing in the predict function of the original model and specifying the number of features to be considered. Finally, it uses the as_pyplot_figure method to display the explanation in a plot and tight_layout() to adjust the layout of the plot.
SHAP (SHapley Additive exPlanations)
Another popular technique for making machine learning models more interpretable is SHAP (SHapley Additive exPlanations). SHAP values provide a way to understand the impact of each feature on the prediction of the model. SHAP values are based on the concept of Shapley values from cooperative game theory. The basic idea is to spread the prediction value among the features and measure the contribution of each feature to the prediction.
Here is a code snippet that demonstrates how to use SHAP to explain the predictions of a machine learning model in Python:
import shap
# train an XGBoost model
X, y = shap.datasets.boston()
model = xgboost.XGBRegressor().fit(X, y)
# explain the model's predictions using SHAP
# (same syntax works for LightGBM, CatBoost, scikit-learn, transformers, Spark, etc.)
explainer = shap.Explainer(model)
shap_values = explainer(X)
# visualize the first prediction's explanation
shap.plots.waterfall(shap_values[0])
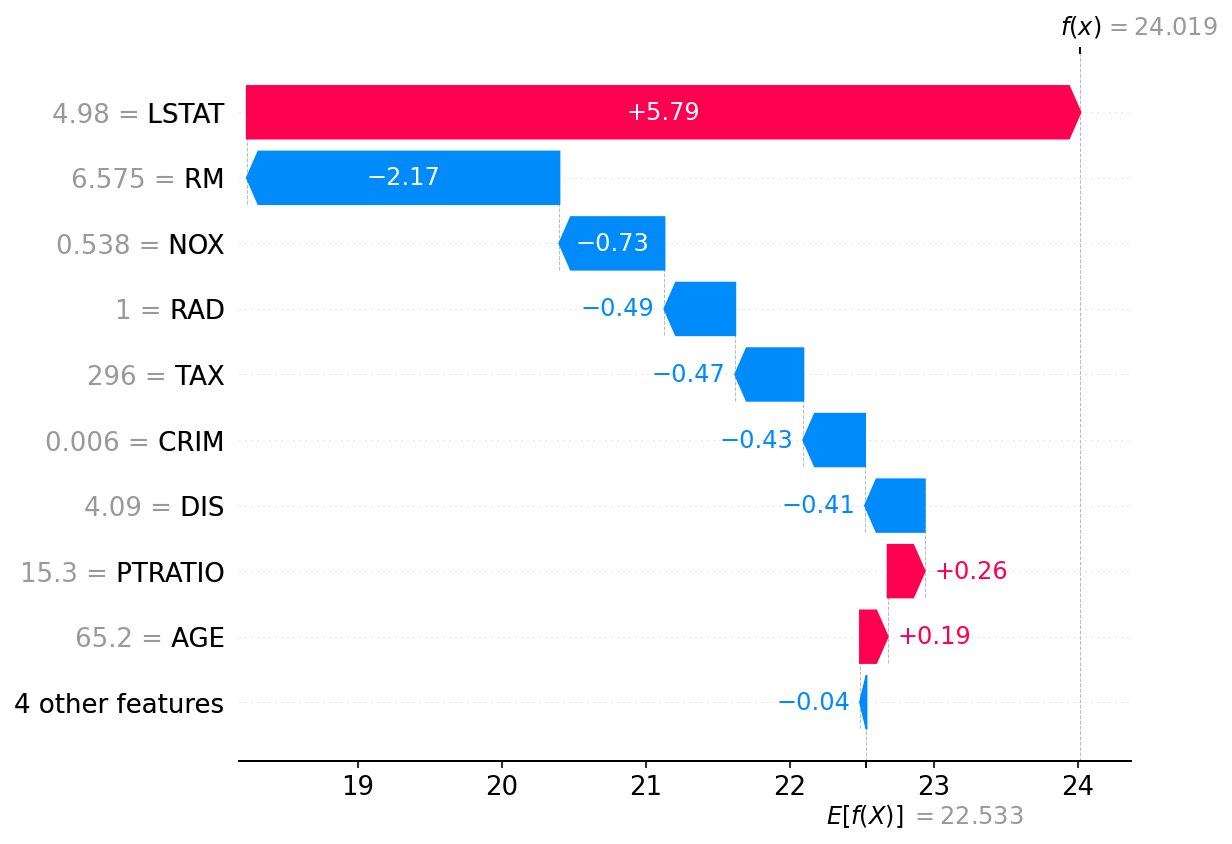
In the above code snippet, we are using the SHAP library to explain the predictions of an XGBoost machine learning model. It loads the boston dataset and train the XGBoost model on that. Then it creates an instance of the Explainer class from the shap library and passing the trained model in it. It then uses this instance to compute the SHAP values for all the instances in the dataset and visualizes the explanation of the first prediction using the waterfall plot from the shap library.
In conclusion, as machine learning models are becoming more complex, it is becoming increasingly important for engineers to be able to understand and interpret the models they are building. Techniques such as LIME and SHAP can be used to understand the model's predictions and identify important features. By providing code snippets, we have shown how these techniques can be applied in practice and how easy it is to use them.
It is important to note that while LIME and SHAP are powerful techniques for making machine learning models more interpretable, they do have some limitations. LIME approximates the model locally, which means that its explanations may not always be representative of the global behavior of the model. SHAP values are based on the concept of Shapley values, which assumes that the features are independent and that the model is a linear function of the features. Therefore, SHAP values may not always accurately reflect the contribution of each feature in non-linear models.
In practice, it is often a good idea to use multiple interpretability techniques in combination to get a more complete understanding of how a model is making predictions. Additionally, it's also important to communicate the results to the stakeholders and domain experts to get their feedback and insights to further improve the model.
Conclusion
In summary, model interpretability is a crucial aspect of machine learning that is becoming increasingly important as models become more complex. Techniques such as LIME and SHAP can be used to make models more interpretable and to better understand how they are making predictions. By providing code snippets, we have shown how easy it is to use these techniques in practice and how they can be applied to real-world problems.