- Published on
Retrieval Augmented Generation: Building LLMs That Know Their Limits
- Authors
- Name
- Parth Maniar
- @theteacoder


The Problem: LLMs and Their Knowledge Boundaries
Large Language Models (LLMs) like GPT-4, Claude, and Llama have transformed how we interact with AI systems. Their ability to generate human-like text across numerous domains is remarkable, but they face a fundamental limitation: they only know what they've been trained on, and their knowledge has a cutoff date.
This leads to two critical issues:
- Knowledge Cutoff: LLMs cannot access information beyond their training data
- Hallucinations: When asked about unfamiliar topics, LLMs often confidently generate plausible-sounding but incorrect information
As these models are deployed in increasingly critical applications, from healthcare to legal assistance, these limitations become not just inconvenient but potentially dangerous.
Enter Retrieval Augmented Generation (RAG)
RAG combines the generative power of LLMs with the ability to retrieve information from external knowledge sources. Instead of relying solely on parametric knowledge (what's encoded in the model's weights), RAG systems can:
- Identify when external information is needed
- Query relevant knowledge bases
- Incorporate the retrieved information into their responses
This approach represents a paradigm shift in how we think about AI language systems.
How RAG Works: A Technical Overview
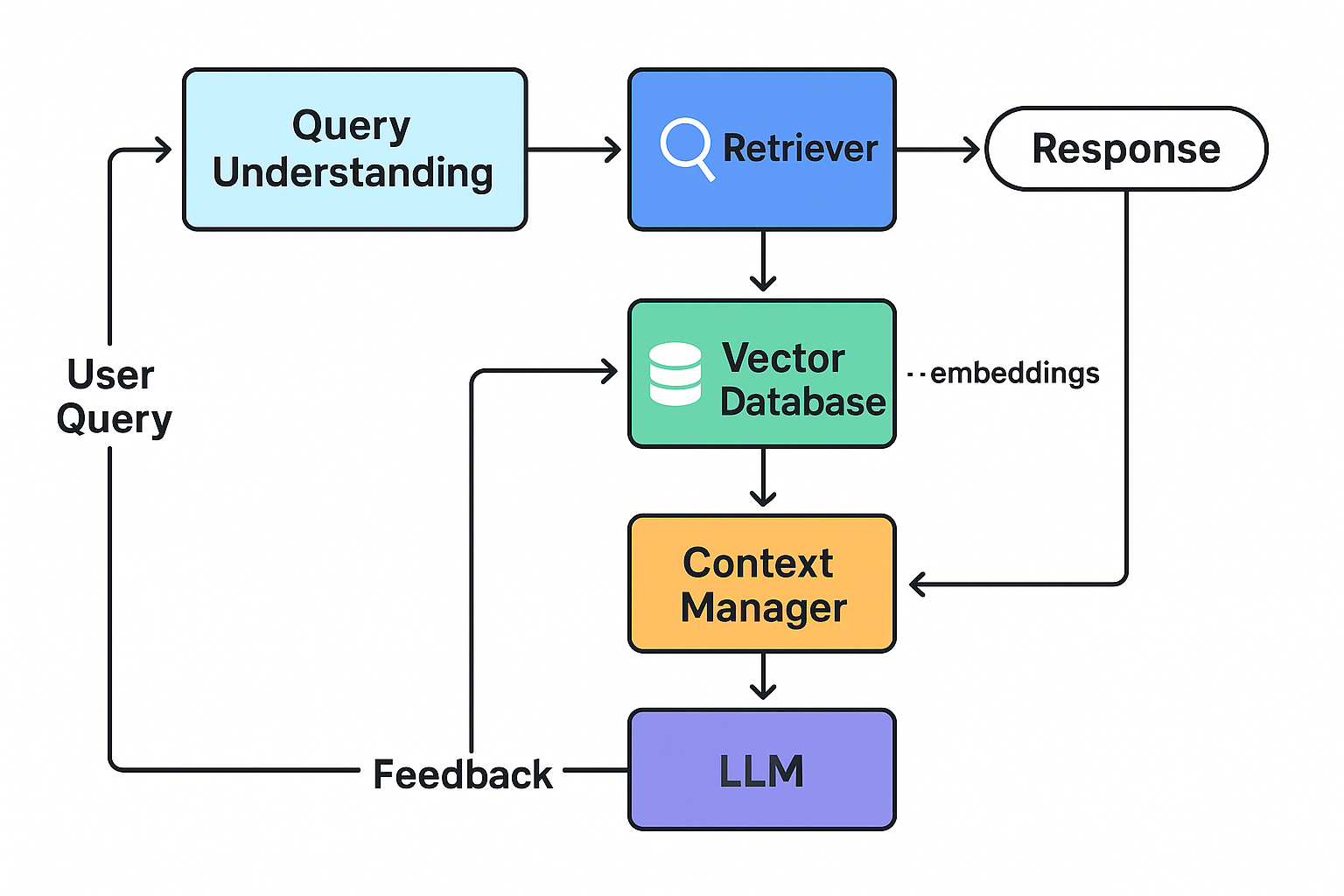
The Core Components
- Query Understanding: The system analyzes the input query to determine what information is needed
- Retrieval System: A vector database or similar system that can efficiently find relevant documents
- Context Window Management: Techniques to efficiently pack retrieved information into the LLM's context
- Generation with Retrieved Context: The LLM generates a response conditioning on both the query and retrieved information
Vector Databases: The Engine of Modern RAG
At the heart of effective RAG systems are vector databases like:
- Pinecone
- Chroma
- Weaviate
- Milvus
- FAISS
These databases store document embeddings—mathematical representations of text that capture semantic meaning—and enable efficient similarity search.
# Example: Basic RAG implementation with OpenAI and Chroma
import openai
import chromadb
from chromadb.utils import embedding_functions
# Set up embedding function
openai_ef = embedding_functions.OpenAIEmbeddingFunction(
api_key="your-openai-key",
model_name="text-embedding-ada-002"
)
# Initialize Chroma client
chroma_client = chromadb.Client()
collection = chroma_client.create_collection(
name="knowledge_base",
embedding_function=openai_ef
)
# Add documents to the collection
collection.add(
documents=["Document about machine learning", "Document about vector databases"],
metadatas=[{"source": "ML textbook"}, {"source": "Database documentation"}],
ids=["doc1", "doc2"]
)
# Query example
query = "How do vector databases work?"
results = collection.query(
query_texts=[query],
n_results=2
)
# Get retrieved contexts
contexts = results["documents"][0]
# Use retrieved contexts with LLM
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Answer based on the following context."},
{"role": "user", "content": f"Context: {contexts}\n\nQuery: {query}"}
]
)
Advanced RAG Techniques
The field is rapidly evolving beyond basic implementations:
1. Hybrid Search
Combining semantic (embedding-based) and lexical (keyword-based) searches improves retrieval effectiveness:
- BM25 or similar algorithms capture exact matches
- Vector search captures semantic similarity
- Hybrid approaches combine both signals for more robust retrieval
2. Re-ranking
Two-stage retrieval pipelines use:
- An initial fast but coarse retrieval step
- A more computationally intensive re-ranking step
Models like Cohere's Rerank and ColBERT can dramatically improve retrieval precision.
3. Multi-vector Retrieval
Instead of representing documents with single vectors:
- Chunk documents into passages
- Embed each passage separately
- Store and retrieve at the passage level
This approach increases retrieval granularity and precision.
4. Self-query Refinement
The LLM can generate its own search queries:
- Generate multiple search queries for the user question
- Execute searches for each query
- Merge and process the results
Measuring RAG System Performance
Evaluating RAG systems requires metrics beyond those used for standard LLMs:
- Retrieval Metrics: Precision, recall, and mean reciprocal rank
- Generation Quality: Factuality, relevance, and helpfulness
- End-to-end Metrics: Task completion rates and user satisfaction
The LlamaIndex and LangChain libraries provide evaluation frameworks specifically designed for RAG systems.
Retrieval Augmented Generation is evolving rapidly:
- Multimodal RAG: Extending beyond text to incorporate images, audio, and video
- Adaptive Retrieval: Systems that dynamically adjust retrieval strategies based on query complexity
- Agent-based RAG: Autonomous systems that orchestrate complex retrieval workflows
- Personalized RAG: Systems that incorporate user context and preferences into the retrieval process
Conclusion
RAG represents a fundamental shift in how we build AI systems that interact with knowledge. By combining the strengths of parametric and non-parametric approaches, RAG systems can deliver more reliable, up-to-date, and transparent responses.
As the field matures, we can expect RAG to become a standard component in most LLM applications, particularly those where factuality and reliability are paramount. The most effective AI systems will be those that know not just how to generate convincing text, but when to retrieve rather than generate—systems that, in essence, know their limits.
References
- Lewis, P., et al. (2020). "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks." NeurIPS 2020.
- Gao, J., et al. (2023). "Retrieval-Augmented Generation for Large Language Models: A Survey." arXiv preprint.
- Liu, J., et al. (2023). "Lost in the Middle: How Language Models Use Long Contexts." arXiv preprint.